ReReadme: Doc-as-CI for Repository Context
Poor Documentation Costs are Rising
In most engineering organizations, distributed systems READMEs are stale at best and nonexistent at worst.
They’re often treated as optional hygiene rather than critical infrastructure. Historically, the cost of poor documentation was absorbed by teams through onboarding friction, tribal knowledge, and informal support. It was inefficient, but tolerable.
That economic model does not scale in an AI-assisted development environment.
Headless coding agents now interact with your repository repeatedly. Each session must reconstruct context that should already exist in a well-written README: architectural boundaries, service responsibilities, deployment constraints, domain assumptions.
Without that context, agents navigate blindly—exploring directories, parsing files, inferring intent, and repeating the cycle. Every cycle consumes tokens, compute, network bandwidth, and time. What used to be onboarding overhead becomes a recurring operational cost.
The absence of structured documentation is no longer a soft inefficiency. It’s measurable spend.
Cost Estimate
Consider a moderately large enterprise repository:
- ~10,000 total files
- ~4,000–5,000 relevant code and configuration files
- Average file size ≈ 4 KB
That yields roughly 16–20 MB of meaningful source text. In practice, a megabyte of code typically corresponds to hundreds of thousands of tokens, depending on formatting and encoding. Even at this conservative scale, the repository still represents millions of tokens of potential context.
Of course, agents rarely ingest the entire repository at once. Instead, they reconstruct context through iterative retrieval and summarization cycles as they explore the system. A realistic orientation pass for a non-trivial service—understanding architecture, build surfaces, deployment paths, and integrations—often consumes 150,000–600,000 tokens per session.
When documentation is missing or outdated, that discovery process repeats every time an agent session begins.
By contrast, a tuned context-gathering workflow can typically generate a high-signal, architecture-aware README in a few hundred thousand tokens once, persisting the key system context for future sessions.
The economics are simple:
pay once to persist context, or pay repeatedly to rediscover it.
Doc-as-CI
A tuned agent workflow focused on gathering that context and persisting it in a README.
The agent explores the repository deliberately, synthesizes context, and persists it as a high-signal README. Because the workflow is CI-friendly, pull requests can be evaluated against the existing documentation to detect drift. Changes that modify behavior without updating docs can be flagged or failed automatically.
Background
The first iteration of this project was a simple inference pipeline: a sequence of OpenAI API calls stitched together to process repository context and emit documentation. It proved the concept, but the design was fundamentally brittle.
It depended on large, precomputed repository dumps. That required constant filtering of low-signal noise: node_modules, lockfiles, generated artifacts, and other irrelevant content. Even with aggressive exclusion rules, the model was still forced to ingest far more context than it actually needed.
The core issue wasn’t prompt quality, it was architecture. So I rebuilt the system around an agentic workflow.
Instead of force-feeding the entire repository, the agent navigates it deliberately. It inspects structure, follows entrypoints, reads configuration surfaces, and incrementally builds an internal model of the system. The behavior is closer to how an experienced engineer explores a codebase: selective, iterative, and context-aware.
Conceptually, this is similar to Claude Code’s /init flow that produces an initial CLAUDE.md. The difference is scope and enforcement. This project treats documentation as a maintained artifact rather than a one-time bootstrap step.
Because the workflow is agent-driven, it extends naturally into CI. Pull requests can be evaluated against the current README to detect documentation drift. Changes that alter behavior without updating docs can be surfaced automatically—or gated entirely.
The result is a repeatable, enforceable pattern for maintaining repository context over time.
Introducing ReReadme
rereadme is a CLI tool that refreshes README.md files by analyzing a repository and generating an updated README from a template using an AI agent workflow built on the OpenAI Agents SDK. It supports both a full regeneration mode and a PR-friendly CI mode that analyzes diffs and produces targeted patch suggestions.
The package focuses on standardized documentation across distributed repositories. In larger organizations, each repository tends to evolve its own documentation style and structure, forcing engineers and agents to re-orient themselves every time they move between services. ReReadme addresses this with bring-your-own templates, allowing teams to define a consistent README structure once and apply it across repositories.
It's not intended to generate flashy Markdown for marketing or virality—that's a different use case entirely. The goal is to help teams quickly establish core documentation where it doesn't exist and then wire a simple process to keep it up to date.
Try it out below:
export OPENAI_API_KEY="your_api_key_here" # See see http://developers.openai.com/api/docs/quickstart/
npm i -g @cjlludwig/rereadme
cd /your/poorly/documented/repo
rereadme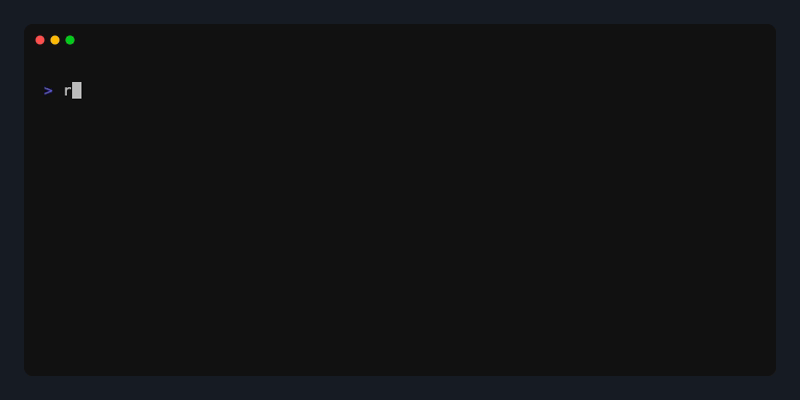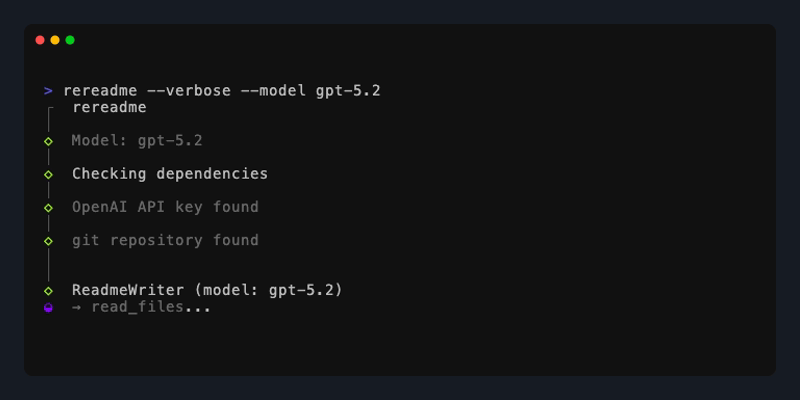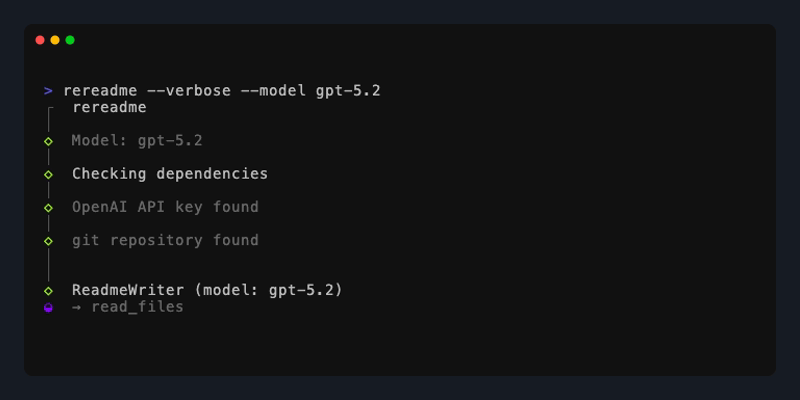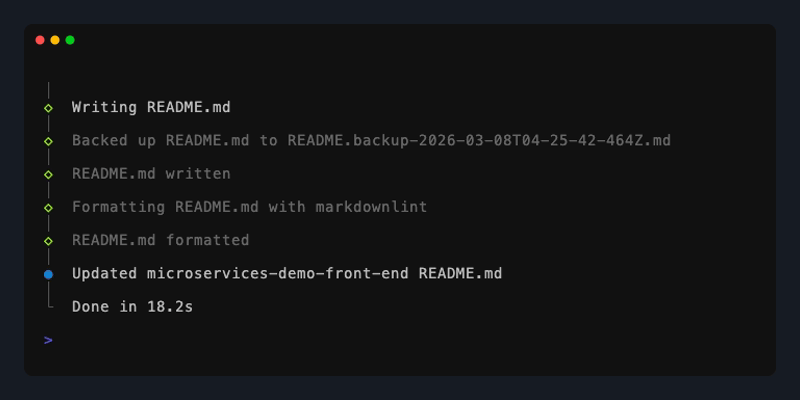
How does it work?
By leveraging the OpenAI Agents SDK I was able to build and tune an agentic workflow exposed as a CLI tool for on-demand documentation generation and evaluation. This keeps the system scoped and predictable, avoiding the unbounded behavior common in many LLM-powered solutions while meeting developers directly in their existing workflows.
Through a curated suite of reusable evals, a representative dataset of repositories, and extensive dogfooding, I developed tuned system prompts for the different agentic tasks in the tool. This setup allows me to quickly validate prompt changes and model upgrades against a standardized benchmark before shipping them.
ReReadme also supports bring-your-own templates using --template, allowing organizations to define a consistent documentation structure across repositories. Instead of every README evolving organically, teams can standardize the sections they care about—architecture, deployment, dependencies, operational notes—and have the agent populate them automatically. See the template docs and the default template example.
Model selection is exposed via the --model flag. The default is pinned to a nano-class model—sufficient to pass the eval suite and keep per-run costs low for most teams. Frontier models consistently produce richer output when quality is the priority.
The agents operate with a deliberately constrained set of filesystem tools built on Node’s native FS capabilities and the globby library. These tools enable targeted repository exploration while enforcing an important constraint: git-tracked access only.
This mirrors normal development practices where only committed files represent the intended state of the repository. By restricting the agent to git-tracked files, sensitive local artifacts like .env, .secrets, and other untracked files remain inaccessible.
The second security principle is isolation. The agent framework runs within your own OpenAI account, meaning repository data never leaves a trusted environment. Combined with the constrained filesystem access, this layered design keeps the system deterministic and dramatically reduces the risk of agent behavior undermining trust in the tool.
Core Workflows
README from scratch
No README? Run rereadme to generate one, the tool explores your repo structure and distills it into a polished doc.
# Before
ls README.md
# ❌ ls: README.md: No such file or directory# After
rereadme --verbose
ls README.md
# ✨ README.md
README drift over time
Stale doc references? Run a check of current Git branch changes against latest README to ensure changes are captured.
git --no-pager diff
# diff --git a/blogs/2-22-26-rereadme.md b/blogs/2-22-26-rereadme.md
# -title: "ReReadme: Doc made simple"
# +title: "ReReadme: Doc-as-ci"
# ... (remaining diff omitted)
rereadme --ci --apply
# ♻️ README.md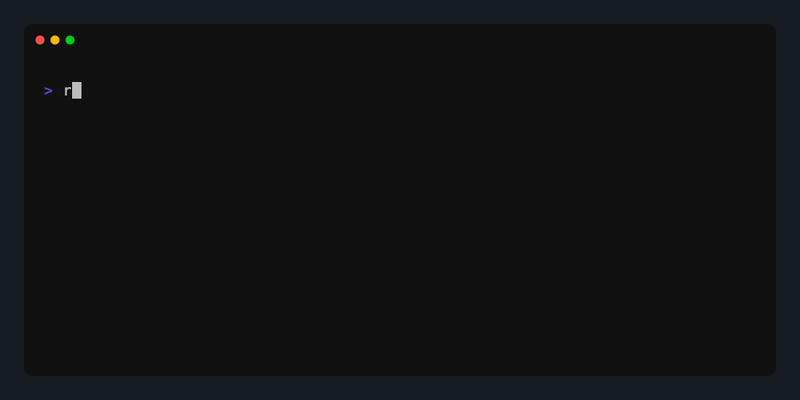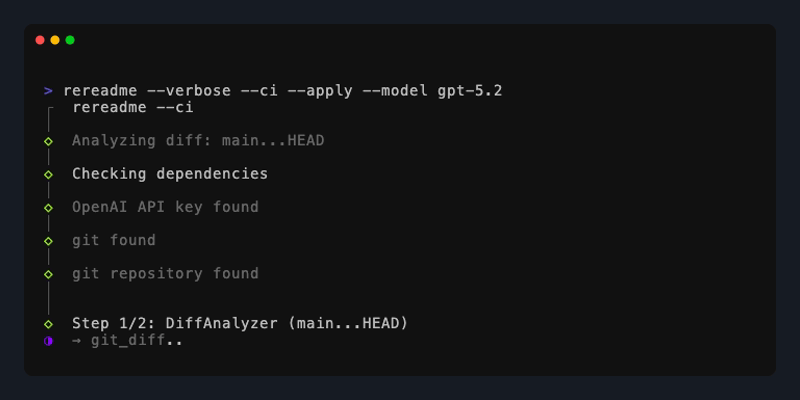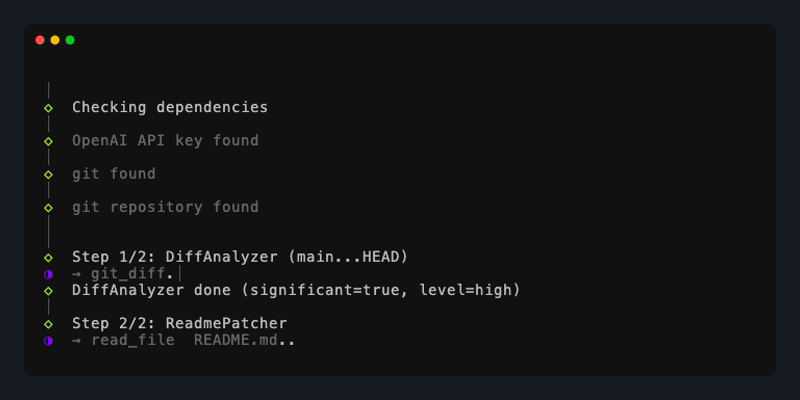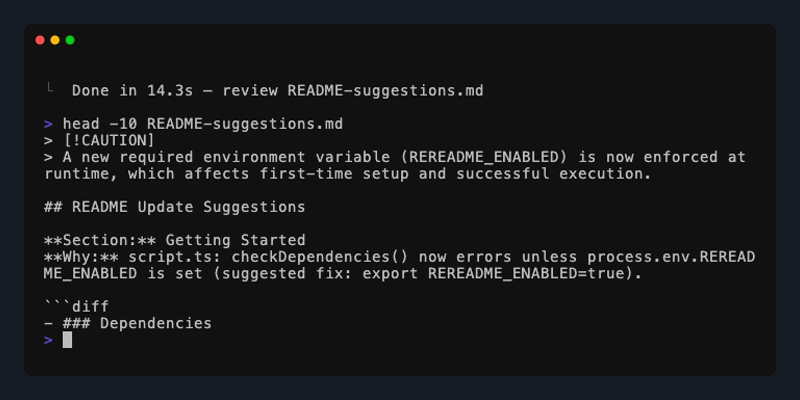
Putting it Together
Documentation used to be a human convenience. In AI-assisted development it becomes shared infrastructure for both humans and agents. ReReadme allows teams to kill two birds with one stone by quickly generating context artifacts for both audiences, dramatically lowering the barrier to entry for any contributor.
I'm planning on continuing to write up a series of lessons learned while tinkering and improving the output of the tool. In these I'll highlight some of the tech decisions made in the repo and the why. These will include:
- Why OpenAI Agents SDK?
- Logging vs Observability decision making
- DevAgent Harness for Improved Quality
- My DevAgent Workflow
- and more!
The tool is ready to use today! Feedback, issues, and contributions are welcome.
Code here: https://github.com/cjlludwig/ReReadme